Embedding Project 2
Types of Recommendation Systems
- Content-Based Recommendation
- Recommends items based on their content (e.g., movie descriptions, metadata).
- Finds similar items by comparing item features.
- Also known as: Similar item recommendation.
- Example: Recommending movies with similar genres or themes based on a movie’s description.
- Collaborative Filtering
- Recommends items based on interactions of similar users.
- Uses user preferences (e.g., likes, ratings) to identify similar users and suggest items the target user hasn’t interacted with.
- Example: Recommending movies rated highly by users with similar tastes.
Building Recommendation Systems
- Content-Based Recommendation
- Approach:
- Generate embeddings for item metadata (e.g., movie descriptions, genres).
- Use semantic similarity to find items close to each other in the embedding space.
- Pros:
- Simple to implement with item metadata.
- Cons:
- Limited diversity in recommendations.
- Ignores user preferences or interaction history.
- Requirements:
- Items with metadata (e.g., movie title, year, actors, genres, tags).
- Approach:
- Collaborative Filtering
- Approach:
- Use user-item interaction data (e.g., ratings, likes).
- Methods include matrix factorization, sparse vector-based filtering, or clustering.
- Pros:
- Personalizes recommendations based on user behavior.
- Cons:
- Requires sufficient user interaction data.
- Requirements:
- Items with user interaction data (e.g., movie ratings).
- Approach:
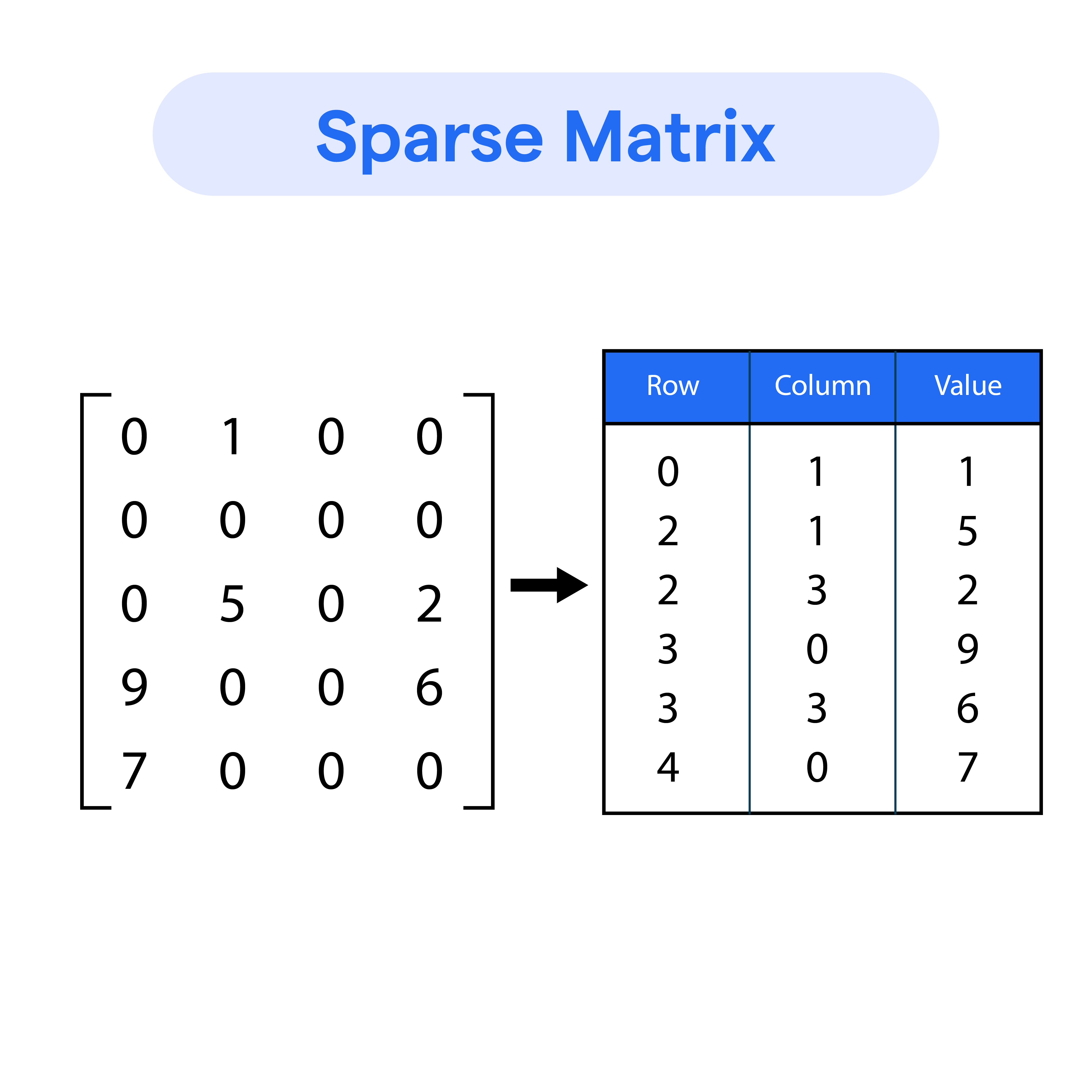
Sparse vs. Dense Vectors
- Sparse and dense vectors are data representation methods used in recommendation systems, image processing, and more.
- Dense Vector
- A matrix where most elements are non-zero.
- Use Cases: Image processing (most are non-zero pixel values), small-scale linear algebra, dense graphs.
- Characteristics: Stores all elements, computationally intensive for large datasets.
- Sparse Vector
- A matrix where most elements are zero.
- Use Cases: Recommendation systems (user-item matrices, where users interact with few items), NLP, network simulations.
- Characteristics: Stores only non-zero elements and their indices, memory-efficient for large datasets.
When to Use
- Dense: Use when fewer than half the elements are zero or for small datasets.
- Sparse: Use when significantly more than half the elements are zero, especially for large datasets, to save memory and computation time.
Collaborative Filtering with Sparse Vectors and Qdrant
Steps to Build
- Obtain Dataset
- Use the MovieLens dataset (smaller version).
- Load and Filter Dataset
- Filter for movies released after 2000 to align with preferences.
- Aggregate Data
- Merge user, movie, and rating data into a single dataset (movies and ratings are stored separately).
- Convert to Sparse Vector
- Represent user-item interactions (e.g., ratings) as a sparse matrix.
- Upload to Qdrant
- Store sparse vectors in Qdrant for efficient similarity search.
- Prepare Sample Ratings
- Create a personal rating list for movies released after 2000, consistent with the filtered dataset.
- Search Qdrant
- Query Qdrant with personal ratings to find similar users or recommended movies.
- The main code
if __name__ == "__main__":
recommender = Recommender()
movies_df, ratings_df = recommender.load_and_filter_data(START_YEAR)
agg_ratings_df = recommender.prepare_ratings_data(movies_df, ratings_df)
sparse_vectors = recommender.convert_to_sparse_vectors(agg_ratings_df)
recommender.setup_collection(delete_existing=True)
recommender.upload_data(sparse_vectors)
# My personal movie ratings (positive: liked, negative: disliked)
# Should be beyond START YEAR
my_ratings = {
78499: 1, # Toy Story 3
78469: 1, # The A-Team
680: 1, # Pulp Fiction
13: 1, # Forrest Gump
102880: -1, # After Earth
120: 1, # Lord of the Rings: The Fellowship of the Ring
180297: -1, # The Disaster Artist
84152: 1, # Limitless
6365: 1, # The Matrix
109487: 1, # Interstellar
135569: 1 # Star Trek Beyond
}
recommendations = recommender.recommend(my_ratings, movies_df, TOP_K)
for title, score, movie_id in recommendations:
print(f"{title}: {score:.3f} (ID: {movie_id})")
- Final output
- in my assessment, I think the recommendations are good
» uv run src/sparse.py
Iron Man (2008): 47.068 (ID: 59315)
Up (2009): 44.028 (ID: 68954)
Avatar (2009): 43.540 (ID: 72998)
Inception (2010): 43.484 (ID: 79132)
Dark Knight, The (2008): 42.536 (ID: 58559)
Lord of the Rings: The Fellowship of the Ring, The (2001): 41.532 (ID: 4993)
Lord of the Rings: The Two Towers, The (2002): 41.532 (ID: 5952)
- Load and filter data
def load_and_filter_data(self, start_year: int) -> Tuple[pd.DataFrame, pd.DataFrame]:
"""
Load movies and ratings, and filter movies by a start year.
"""
movies_df = pd.read_csv(MOVIES_CSV, low_memory=False)
ratings_df = pd.read_csv(RATINGS_CSV, low_memory=False)
movies_df['year'] = pd.to_numeric(
movies_df['title'].str.extract(r'\((\d{4})\)', expand=False),
errors='coerce'
)
movies_df = movies_df.dropna(subset=['year']).copy()
movies_df['year'] = movies_df['year'].astype(int)
filtered_movies = movies_df[movies_df['year'] >= start_year].copy()
valid_movie_ids = filtered_movies['movieId'].unique()
filtered_ratings = ratings_df[ratings_df['movieId'].isin(valid_movie_ids)].copy()
return filtered_movies, filtered_ratings
- Aggregating our data
def prepare_ratings_data(self, movies_df: pd.DataFrame, ratings_df: pd.DataFrame) -> pd.DataFrame:
"""
Normalize and merge ratings with movies metadata.
"""
ratings_df['movieId'] = ratings_df['movieId'].astype(str)
movies_df['movieId'] = movies_df['movieId'].astype(str)
ratings_df['rating'] = (ratings_df['rating'] - ratings_df['rating'].mean()) / ratings_df['rating'].std()
merged_df = ratings_df.merge(
movies_df[['movieId', 'title']],
on='movieId',
how='inner'
)
return merged_df.groupby(['userId', 'movieId'])['rating'].mean().reset_index()
#sample aggregate output(agg_ratings_df.head())
userId movieId rating
0 1 3273 1.492132
1 1 3578 1.492132
2 1 3617 0.516044
3 1 3744 0.516044
4 1 3793 1.492132
- Convert to sparse vector
def convert_to_sparse_vectors(self, agg_data: pd.DataFrame) -> Dict[int, Dict[str, List[float]]]:
"""
Convert user ratings into sparse vectors.
"""
sparse_vectors = defaultdict(lambda: {"values": [], "items": []})
for row in agg_data.itertuples():
sparse_vectors[row.userId]["items"].append(int(row.movieId))
sparse_vectors[row.userId]["values"].append(row.rating)
return sparse_vectors
- Setup Qdrant collection and upload the vector data.
def setup_collection(self, delete_existing: bool = True) -> None:
"""
Create or reset the Qdrant collection for storing sparse vectors.
"""
if delete_existing and self.client.collection_exists(COLLECTION_NAME):
self.client.delete_collection(COLLECTION_NAME)
self.client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config={},
sparse_vectors_config={"ratings": models.SparseVectorParams()}
)
def upload_data(self, sparse_vectors: Dict[int, Dict[str, List[float]]]) -> None:
"""
Upload sparse vectors to Qdrant collection.
"""
self.client.upload_points(
collection_name=COLLECTION_NAME,
points=self.generate_points(sparse_vectors)
)
def generate_points(self, sparse_vectors) -> Generator[PointStruct, None, None]:
"""
Generate Qdrant PointStruct objects for each user.
"""
for user_id, vec in sparse_vectors.items():
yield PointStruct(
id=user_id,
vector={"ratings": SparseVector(
indices=vec["items"],
values=vec["values"]
)
},
payload={"user_id": user_id, "movie_id": vec["items"]}
)
- Recommendations
def recommend(
self,
my_ratings: Dict[int, float],
movies_df: pd.DataFrame,
top_k: int
) -> List[Tuple[str, float, int]]:
"""
Generate top-k movie recommendations based on user's ratings.
"""
results = self.client.search(
collection_name=COLLECTION_NAME,
query_vector=NamedSparseVector(name="ratings", vector=self.to_sparse_vector(my_ratings)),
limit=20
)
movie_scores = self.get_unique_movie_scores(my_ratings, results)
top_movies = sorted(movie_scores.items(), key=lambda x: x[1], reverse=True)[:top_k]
recommendations: List[Tuple[str, float, int]] = []
for movie_id, score in top_movies:
movie_row = movies_df[movies_df["movieId"] == str(movie_id)]
if not movie_row.empty:
recommendations.append((movie_row["title"].iloc[0], score, movie_id))
return recommendations
def get_unique_movie_scores(
self,
previous_ratings: Dict[int, float],
results: List[models.ScoredPoint]
) -> Dict[int, float]:
"""
Score movies not already rated by user.
"""
movie_scores = defaultdict(float)
for result in results:
for movie_id in result.payload["movie_id"]:
if movie_id not in previous_ratings:
movie_scores[movie_id] += result.score
return movie_scores